This tutorial describes the usage of regular expressions in Java with modern examples and best practices. It covers basic regex syntax, Java’s Pattern and Matcher classes, practical examples for common use cases, and important security considerations.
1. Regular Expressions
1.1. What are regular expressions?
A regular expression (regex) defines a search pattern for strings. The search pattern can be anything from a simple character, a fixed string or a complex expression containing special characters describing the pattern.
A regex can be used to search, edit and manipulate text, this process is called: The regular expression is applied to the text/string.
The regex is applied on the text from left to right.
Once a source character has been used in a match, it cannot be reused.
For example, the regex aba will match ababababa only two times (aba_aba__).
1.2. Common use cases for regular expressions
Regular expressions are powerful tools for text processing and are commonly used in:
-
Data validation: Validating email addresses, phone numbers, credit card numbers, postal codes
-
Text parsing: Extracting specific information from log files, configuration files, or structured text
-
Search and replace: Finding and replacing patterns in text editors, IDEs, and scripts
-
Data cleaning: Removing unwanted characters, normalizing formats, or standardizing data
-
Web scraping: Extracting structured data from HTML content
-
Log analysis: Parsing log entries to extract timestamps, error codes, and messages
-
Input sanitization: Cleaning user input to prevent security vulnerabilities
1.3. Regex examples
A simple example for a regular expression is a (literal) string.
For example, the Hello World regex matches the "Hello World" string.
. (dot) is another example for a regular expression.
A dot matches any single character; it would match, for example, "a" or "1".
The following tables lists several regular expressions and describes which pattern they would match.
| Regex | Matches |
|---|---|
this is text |
Matches exactly "this is text" |
this\s+is\s+text |
Matches the word "this" followed by one or more whitespace characters followed by the word "is" followed by one or more whitespace characters followed by the word "text". |
^\d+(\.\d+)? |
^ defines that the pattern must start at beginning of a new line. \d+ matches one or several digits. The ? makes the statement in brackets optional. \. matches ".", parentheses are used for grouping. Matches for example "5", "1.5" and "2.21". |
^@[a-zA-Z0-9.-]\.[a-zA-Z]{2,}$ |
Email validation pattern that matches most common email formats. Starts with word characters, followed by @, domain name, and TLD. |
\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b |
Basic IPv4 address pattern matching four groups of 1-3 digits separated by dots (note: this doesn’t validate ranges). |
(\+\d{1,3}\s?)?\(?\d{3}\)?[\s.-]?\d{3}[\s.-]?\d{4} |
Phone number pattern supporting various formats including country codes, area codes with/without parentheses, and different separators. |
1.4. Performance considerations
When using regular expressions in Java applications, consider these performance tips:
-
Compile patterns once: Use
Pattern.compile()to create reusable pattern objects rather than using String methods repeatedly -
Avoid catastrophic backtracking: Be careful with nested quantifiers like
(a+)+which can cause exponential time complexity -
Use non-capturing groups: When you don’t need to extract the matched text, use
(?:…)instead of(…) -
Consider alternatives: For simple string operations, native String methods might be faster than regex
-
Profile in context: Test regex performance with your actual data patterns and sizes
2. Prerequisites
The following tutorial assumes that you have basic knowledge of the Java programming language.
This tutorial uses modern Java features (Java 17+) including the var keyword, text blocks, and enhanced APIs.
The examples use JUnit 5 for testing and validation. If you’re not familiar with JUnit 5, you can still follow the examples and adapt them to your preferred testing framework.
2.1. Java version requirements
-
Minimum: Java 8 (for basic regex functionality)
-
Recommended: Java 17+ (for modern features used in examples)
-
Dependencies: JUnit 5 for running tests (optional)
If you’re using an older Java version, you can adapt the examples by:
* Replacing var with explicit types
* Using string concatenation instead of text blocks
* Using JUnit 4 annotations instead of JUnit 5
3. Rules of writing regular expressions
The following description is an overview of available meta characters that can be used in regular expressions. This chapter serves as a reference for the different regex elements.
3.1. Common matching symbols
| Regular Expression | Description |
|---|---|
|
Matches any character |
|
Finds regex that must match at the beginning of the line. |
|
Finds regex that must match at the end of the line. |
|
Set definition, can match the letter a or b or c. |
|
Set definition, can match a or b or c followed by either v or z. |
|
When a caret appears as the first character inside square brackets, it negates the pattern. This pattern matches any character except a or b or c. |
|
Ranges: matches a letter between a and d and figures from 1 to 7, but not d1. |
|
Finds X or Z. |
|
Finds X directly followed by Z. |
|
Checks if a line end follows. |
3.2. Meta characters
The following meta characters have a predefined meaning and make certain common patterns easier to use.
For example, you can use \d as simplified definition for [0..9].
| Regular Expression | Description |
|---|---|
|
Any digit, short for |
|
A non-digit, short for |
|
A whitespace character, short for |
|
A non-whitespace character, short for |
|
A word character, short for |
|
A non-word character |
|
Several non-whitespace characters |
|
Matches a word boundary where a word character is |
| These meta characters have the same first letter as their representation, e.g., digit, space, word, and boundary. Uppercase symbols define the opposite. |
3.3. Quantifier
A quantifier defines how often an element can occur. The symbols ?, *, + and {} are quantifiers.
| Regular Expression | Description | Examples |
|---|---|---|
|
Occurs zero or more times, is short for |
|
|
Occurs one or more times, is short for |
|
|
Occurs no or one times, |
|
|
Occurs X number of times, |
|
|
Occurs between X and Y times, |
|
|
|
3.4. Grouping and back reference
You can group parts of your regular expression.
In your pattern you group elements with round brackets, e.g., ().
This allows you to assign a repetition operator to a complete group.
In addition these groups also create a back reference to the part of the regular expression.
This captures the group.
A back reference stores the part of the String which matched the group.
This allows you to use this part in the replacement.
Via the $ you can refer to a group.
$1 is the first group, $2 the second, etc.
Let’s, for example, assume you want to replace all whitespace between a letter followed by a point or a comma. This would involve that the point or the comma is part of the pattern. Still it should be included in the result.
// Removes whitespace between a word character and . or ,
String pattern = "(\\w)(\\s+)([\\.,])";
System.out.println(EXAMPLE_TEST.replaceAll(pattern, "$1$3"));This example extracts the text between a title tag.
// Extract the text between the two title elements
pattern = "(?i)(<title.*?>)(.+?)()";
String updated = EXAMPLE_TEST.replaceAll(pattern, "$2");3.5. Negative look ahead
Negative look ahead provides the possibility to exclude a pattern. With this you can say that a string should not be followed by another string.
Negative look ahead are defined via (?!pattern).
For example, the following will match "a" if "a" is not followed by "b".
a(?!b)3.6. Specifying modes inside the regular expression
You can add the mode modifiers to the start of the regex. To specify multiple modes, put them together as in (?ismx).
-
(?i) makes the regex case insensitive.
-
(?s) for "single line mode" makes the dot match all characters, including line breaks.
-
(?m) for "multi-line mode" makes the caret and dollar match at the start and end of each line in the subject string.
3.7. Backslashes in Java
The backslash \ is an escape character in Java Strings.
That means backslash has a predefined meaning in Java.
You have to use double backslash \\ to define a single backslash.
If you want to define \w, then you must be using \\w in your regex.
If you want to use backslash as a literal, you have to type \\\\ as \ is also an escape character in regular expressions.
4. Using regular expressions with String methods
4.1. Redefined methods on String for processing regular expressions
Strings in Java have built-in support for regular expressions.
Strings have four built-in methods for regular expressions:
* matches(),
* split(),
* replaceFirst()
* replaceAll()
The replace() method does NOT support regular expressions.
These methods are not optimized for performance. We will later use classes that are optimized for performance.
| Method | Description |
|---|---|
|
Evaluates if |
|
Creates an array with substrings of |
|
Replaces the first substring that matches "regex" with "replacement". |
|
Replaces all substrings that match "regex" with "replacement". |
Create for the following example the Java project
de.vogella.regex.test.
package de.vogella.regex.test;
import java.util.Arrays;
/**
* Demonstrates basic regex operations using String methods.
* This example shows the fundamental regex support built into Java Strings.
*/
public class RegexTestStrings {
public static final String EXAMPLE_TEXT = """
This is my small example string which I'm going to use for pattern matching.
""".trim();
public static void main(String[] args) {
System.out.println("=== String Regex Methods Demo ===");
System.out.println("Example text: " + EXAMPLE_TEXT);
System.out.println();
// Test if string starts with a word character
var startsWithWord = EXAMPLE_TEXT.matches("\\w.*");
System.out.println("Starts with word character: " + startsWithWord);
// Split the string by whitespace
String[] words = EXAMPLE_TEXT.split("\\s+");
System.out.println("Number of words: " + words.length);
System.out.println("Words: " + Arrays.toString(words));
// Replace all whitespace with tabs
var tabSeparated = EXAMPLE_TEXT.replaceAll("\\s+", "\t");
System.out.println("Tab-separated: " + tabSeparated);
// Find and replace first occurrence
var firstReplacement = EXAMPLE_TEXT.replaceFirst("small", "LARGE");
System.out.println("First replacement: " + firstReplacement);
// Multiple replacements example
var cleaned = EXAMPLE_TEXT
.replaceAll("\\s+", " ") // normalize whitespace
.replaceAll("'", "'"); // normalize apostrophes
System.out.println("Cleaned text: " + cleaned);
}
}4.2. Examples
The following class gives several examples for the usage of regular expressions with strings. See the comment for the purpose.
If you want to test these examples, create for
the Java project
de.vogella.regex.string.
package de.vogella.regex.string;
import java.util.regex.Pattern;
/**
* StringMatcher demonstrates common string matching patterns using regular expressions.
* This class showcases various regex patterns for typical validation scenarios.
*/
public class StringMatcher {
// Pre-compiled patterns for better performance
private static final Pattern TRUE_PATTERN = Pattern.compile("true");
private static final Pattern TRUE_CASE_INSENSITIVE = Pattern.compile("[tT]rue");
private static final Pattern TRUE_OR_YES = Pattern.compile("[tT]rue|[yY]es");
private static final Pattern THREE_LETTERS = Pattern.compile("[a-zA-Z]{3}");
private static final Pattern NO_NUMBER_START = Pattern.compile("^[^\\d].*");
private static final Pattern WORD_EXCEPT_B = Pattern.compile("([\\w&&[^b]])*");
private static final Pattern LESS_THAN_300 = Pattern.compile("[^0-9]*[12]?[0-9]{1,2}[^0-9]*");
/**
* Returns true if the string matches exactly "true"
* @param input the string to test
* @return true if exact match for "true"
*/
public boolean isTrue(String input) {
return TRUE_PATTERN.matcher(input).matches();
}
/**
* Returns true if the string matches exactly "true" or "True" (case-insensitive first letter)
* @param input the string to test
* @return true if matches "true" or "True"
*/
public boolean isTrueVersion2(String input) {
return TRUE_CASE_INSENSITIVE.matcher(input).matches();
}
/**
* Returns true if the string matches exactly "true", "True", "yes", or "Yes"
* @param input the string to test
* @return true if matches any of the allowed values
*/
public boolean isTrueOrYes(String input) {
return TRUE_OR_YES.matcher(input).matches();
}
/**
* Returns true if the string contains "true" anywhere within it
* @param input the string to test
* @return true if "true" is found anywhere in the string
*/
public boolean containsTrue(String input) {
return input.matches(".*true.*");
}
/**
* Returns true if the string consists of exactly three letters
* @param input the string to test
* @return true if exactly three alphabetic characters
*/
public boolean isThreeLetters(String input) {
return THREE_LETTERS.matcher(input).matches();
}
/**
* Returns true if the string does not have a number at the beginning
* @param input the string to test
* @return true if first character is not a digit
*/
public boolean isNoNumberAtBeginning(String input) {
return NO_NUMBER_START.matcher(input).matches();
}
/**
* Returns true if the string contains only word characters except 'b'
* Uses intersection pattern [\\w&&[^b]] - word chars AND not 'b'
* @param input the string to test
* @return true if contains only word characters excluding 'b'
*/
public boolean isIntersection(String input) {
return WORD_EXCEPT_B.matcher(input).matches();
}
/**
* Returns true if the string contains a number less than 300
* This regex handles numbers embedded in text
* @param input the string to test
* @return true if contains a number less than 300
*/
public boolean isLessThanThreeHundred(String input) {
return LESS_THAN_300.matcher(input).matches();
}
}And a small JUnit Test to validate the examples.
package de.vogella.regex.string;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertTrue;
@DisplayName("String Matcher Regular Expression Tests")
public class StringMatcherTest {
private StringMatcher matcher;
@BeforeEach
void setUp() {
matcher = new StringMatcher();
}
@Test
@DisplayName("Should match exact 'true' string")
void testIsTrue() {
assertTrue(matcher.isTrue("true"));
assertFalse(matcher.isTrue("true2"));
assertFalse(matcher.isTrue("True"));
assertFalse(matcher.isTrue(" true "));
}
@Test
@DisplayName("Should match 'true' case-insensitive")
void testIsTrueVersion2() {
assertTrue(matcher.isTrueVersion2("true"));
assertFalse(matcher.isTrueVersion2("true2"));
assertTrue(matcher.isTrueVersion2("True"));
}
@ParameterizedTest
@DisplayName("Should match 'true' or 'yes' case-insensitive")
@ValueSource(strings = {"true", "True", "yes", "Yes"})
void testIsTrueOrYesValid(String input) {
assertTrue(matcher.isTrueOrYes(input));
}
@ParameterizedTest
@DisplayName("Should not match invalid inputs for 'true' or 'yes'")
@ValueSource(strings = {"no", "maybe", "false", "TRUE", "YES"})
void testIsTrueOrYesInvalid(String input) {
assertFalse(matcher.isTrueOrYes(input));
}
@Test
@DisplayName("Should find 'true' anywhere in string")
void testContainsTrue() {
assertTrue(matcher.containsTrue("thetruewithin"));
assertTrue(matcher.containsTrue("true"));
assertTrue(matcher.containsTrue("start true end"));
assertFalse(matcher.containsTrue("Truth"));
assertFalse(matcher.containsTrue("untrue"));
}
@ParameterizedTest
@DisplayName("Should match exactly three letters")
@ValueSource(strings = {"abc", "XYZ", "DeF"})
void testIsThreeLettersValid(String input) {
assertTrue(matcher.isThreeLetters(input));
}
@ParameterizedTest
@DisplayName("Should not match non-three-letter strings")
@ValueSource(strings = {"ab", "abcd", "123", "ab1", "a b"})
void testIsThreeLettersInvalid(String input) {
assertFalse(matcher.isThreeLetters(input));
}
@Test
@DisplayName("Should validate strings don't start with numbers")
void testNoNumberAtBeginning() {
assertTrue(matcher.isNoNumberAtBeginning("abc"));
assertFalse(matcher.isNoNumberAtBeginning("1abcd"));
assertTrue(matcher.isNoNumberAtBeginning("a1bcd"));
assertTrue(matcher.isNoNumberAtBeginning("asdfdsf"));
assertFalse(matcher.isNoNumberAtBeginning("9test"));
}
@Test
@DisplayName("Should match intersection pattern (word chars except 'b')")
void testIntersection() {
assertTrue(matcher.isIntersection("1"));
assertTrue(matcher.isIntersection("acdefg"));
assertFalse(matcher.isIntersection("abc"));
assertTrue(matcher.isIntersection("skdskfjsmcnxmvjwque484242"));
assertFalse(matcher.isIntersection("hobbit"));
}
@Test
@DisplayName("Should validate numbers less than 300")
void testLessThanThreeHundred() {
assertTrue(matcher.isLessThanThreeHundred("288"));
assertFalse(matcher.isLessThanThreeHundred("3288"));
assertFalse(matcher.isLessThanThreeHundred("328 8"));
assertTrue(matcher.isLessThanThreeHundred("1"));
assertTrue(matcher.isLessThanThreeHundred("99"));
assertFalse(matcher.isLessThanThreeHundred("300"));
assertTrue(matcher.isLessThanThreeHundred("299"));
assertFalse(matcher.isLessThanThreeHundred("301"));
}
}5. Pattern and Matcher
For advanced regular expressions, the java.util.regex.Pattern and java.util.regex.Matcher classes provide better performance and more functionality than String methods.
You first create a Pattern object that defines the regular expression using Pattern.compile().
This Pattern object allows you to create a Matcher object for a given string.
This Matcher object then allows you to perform various regex operations on a String.
package de.vogella.regex.test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Demonstrates advanced regex operations using Pattern and Matcher classes.
* This approach provides better performance and more functionality than String methods.
*/
public class RegexTestPatternMatcher {
public static final String EXAMPLE_TEXT = """
This is my small example string which I'm going to use for pattern matching.
""".trim();
public static void main(String[] args) {
System.out.println("=== Pattern and Matcher Demo ===");
System.out.println("Example text: " + EXAMPLE_TEXT);
System.out.println();
// Pattern for finding words - compile once, use multiple times
var wordPattern = Pattern.compile("\\w+");
// For case-insensitive matching, you can use:
// Pattern wordPattern = Pattern.compile("\\w+", Pattern.CASE_INSENSITIVE);
var matcher = wordPattern.matcher(EXAMPLE_TEXT);
System.out.println("=== Finding all words ===");
// Find all occurrences
while (matcher.find()) {
System.out.printf("Found '%s' at positions %d-%d%n",
matcher.group(), matcher.start(), matcher.end());
}
System.out.println();
System.out.println("=== Replacing whitespace with tabs ===");
// Create pattern for whitespace replacement
var whitespacePattern = Pattern.compile("\\s+");
var whitespaceMatcher = whitespacePattern.matcher(EXAMPLE_TEXT);
var result = whitespaceMatcher.replaceAll("\t");
System.out.println("Result: " + result);
System.out.println();
System.out.println("=== Advanced Pattern Matching ===");
// More complex pattern - finding words that start with specific letters
var specificPattern = Pattern.compile("\\b[smw]\\w*", Pattern.CASE_INSENSITIVE);
var specificMatcher = specificPattern.matcher(EXAMPLE_TEXT);
System.out.println("Words starting with 's', 'm', or 'w':");
while (specificMatcher.find()) {
System.out.printf(" '%s' at position %d%n",
specificMatcher.group(), specificMatcher.start());
}
}
}5.1. Pattern compilation and flags
Pattern compilation is an expensive operation, so you should compile patterns once and reuse them. Pattern objects are thread-safe and can be shared between threads.
// Compile once, use many times
Pattern emailPattern = Pattern.compile(
"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$",
Pattern.CASE_INSENSITIVE | Pattern.UNICODE_CASE
);
// Use with different inputs
boolean isValid1 = emailPattern.matcher("User@Example.COM").matches();
boolean isValid2 = emailPattern.matcher("test@domain.org").matches();Common pattern flags include:
-
Pattern.CASE_INSENSITIVE: Case-insensitive matching -
Pattern.MULTILINE:^and$match line boundaries instead of string boundaries -
Pattern.DOTALL:.matches any character including line terminators -
Pattern.UNICODE_CASE: Unicode-aware case folding -
Pattern.COMMENTS: Whitespace and comments in patterns are ignored
5.2. Matcher methods and functionality
The Matcher class provides several useful methods:
String text = "Call 555-1234 or 555-5678 for support";
Pattern phonePattern = Pattern.compile("\\d{3}-\\d{4}");
Matcher matcher = phonePattern.matcher(text);
// Find all matches
while (matcher.find()) {
System.out.printf("Found '%s' at position %d-%d%n",
matcher.group(), matcher.start(), matcher.end());
}
// Reset and replace
matcher.reset();
String result = matcher.replaceAll("XXX-XXXX");
System.out.println("Masked: " + result);
// Check if entire string matches
boolean fullMatch = phonePattern.matcher("555-1234").matches();
// Check if string contains pattern
boolean contains = phonePattern.matcher("Call 555-1234").find();5.3. Groups and capturing
Groups allow you to extract parts of the matched text:
String logEntry = "2024-01-15 10:30:45 [ERROR] Connection failed";
Pattern logPattern = Pattern.compile(
"(\\d{4}-\\d{2}-\\d{2})\\s+(\\d{2}:\\d{2}:\\d{2})\\s+\\[(\\w+)\\]\\s+(.+)"
);
Matcher matcher = logPattern.matcher(logEntry);
if (matcher.matches()) {
String date = matcher.group(1); // "2024-01-15"
String time = matcher.group(2); // "10:30:45"
String level = matcher.group(3); // "ERROR"
String message = matcher.group(4); // "Connection failed"
System.out.printf("Date: %s, Time: %s, Level: %s, Message: %s%n",
date, time, level, message);
}5.4. Performance tips
-
Compile patterns once: Store compiled patterns as static final fields
-
Use specific quantifiers:
{n,m}is often faster than*or+ -
Avoid nested quantifiers: Patterns like
(a+)+can cause exponential backtracking -
Use non-capturing groups:
(?:…)when you don’t need to extract the text -
Consider alternatives: For simple operations, String methods might be faster
6. Java Regex Examples
The following lists typical examples for the usage of regular expressions in modern Java applications. These examples demonstrate practical patterns for common development scenarios including data validation, text parsing, and content extraction.
6.1. Or
Task: Write a regular expression which matches a text line if this text line contains either the word "Joe" or the word "Jim" or both.
Create a project
de.vogella.regex.eitheror
and the following class.
package de.vogella.regex.eitheror;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertTrue;
/**
* Demonstrates the OR operator (|) in regular expressions.
* This example shows how to match multiple alternative patterns.
*/
@DisplayName("Either/Or Pattern Matching Tests")
public class EitherOrCheck {
@ParameterizedTest
@DisplayName("Should match strings containing 'jim' or 'joe'")
@ValueSource(strings = {
"humbapumpa jim",
"humbaPumpa joe",
"humbapumpa joe jim",
"jim is here",
"where is joe?",
"both jim and joe are here"
})
void testMatchesJimOrJoe(String input) {
assertTrue(input.matches(".*(jim|joe).*"),
"Should match strings containing 'jim' or 'joe': " + input);
}
@ParameterizedTest
@DisplayName("Should not match strings without 'jim' or 'joe'")
@ValueSource(strings = {
"humbapumpa jom",
"hello world",
"jamie and joel", // similar but not exact matches
"jimbo and joey" // contains the letters but not the exact words
})
void testDoesNotMatchOtherStrings(String input) {
assertFalse(input.matches(".*(jim|joe).*"),
"Should not match strings without exact 'jim' or 'joe': " + input);
}
@Test
@DisplayName("Demonstrate case-sensitive vs case-insensitive matching")
void testCaseSensitivity() {
var text = "Hello JIM and JOE";
// Case-sensitive (should fail)
assertFalse(text.matches(".*(jim|joe).*"),
"Case-sensitive matching should fail for uppercase");
// Case-insensitive (should pass)
assertTrue(text.matches("(?i).*(jim|joe).*"),
"Case-insensitive matching should work for uppercase");
}
@Test
@DisplayName("More complex OR patterns with word boundaries")
void testWordBoundaryMatching() {
// Using word boundaries to match exact words only
var pattern = "\\b(jim|joe|james|joseph)\\b";
assertTrue("jim".matches(pattern), "Should match exact word 'jim'");
assertTrue("joe".matches(pattern), "Should match exact word 'joe'");
assertTrue("james".matches(pattern), "Should match exact word 'james'");
assertTrue("joseph".matches(pattern), "Should match exact word 'joseph'");
assertFalse("jimmy".matches(pattern), "Should not match partial word 'jimmy'");
assertFalse("joey".matches(pattern), "Should not match partial word 'joey'");
}
}6.2. Phone number
Task: Write a regular expression which matches any phone number.
A phone number in this example consists either out of 7 numbers in a row or out of 3 number, a (white)space or a dash and then 4 numbers.
package de.vogella.regex.phonenumber;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
import java.util.regex.Pattern;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertTrue;
/**
* Demonstrates phone number validation using regular expressions.
* Includes patterns for various international and US phone number formats.
*/
@DisplayName("Phone Number Validation Tests")
public class CheckPhone {
// US phone number patterns
private static final Pattern US_PHONE_SIMPLE = Pattern.compile("\\d{3}[,\\s]?\\d{4}");
private static final Pattern US_PHONE_FULL = Pattern.compile("\\(?\\d{3}\\)?[-\\s]?\\d{3}[-\\s]?\\d{4}");
// International phone number pattern (basic)
private static final Pattern INTERNATIONAL_PHONE = Pattern.compile("\\+?\\d{1,4}[-\\s]?\\(?\\d{1,4}\\)?[-\\s]?\\d{1,4}[-\\s]?\\d{1,9}");
@Test
@DisplayName("Test simple 7-digit phone pattern")
void testSimplePhonePattern() {
var pattern = "\\d{3}[,\\s]?\\d{4}";
// Valid 7-digit numbers
assertTrue("1233323".matches(pattern), "Should match 7 digits");
assertTrue("123 3323".matches(pattern), "Should match with space");
assertTrue("123,3323".matches(pattern), "Should match with comma");
// Invalid patterns
assertFalse("1233323322".matches(pattern), "Should not match 10 digits");
assertFalse("12333".matches(pattern), "Should not match 5 digits");
}
@ParameterizedTest
@DisplayName("Test US phone number formats")
@ValueSource(strings = {
"123-456-7890",
"(123) 456-7890",
"(123)456-7890",
"123 456 7890",
"1234567890"
})
void testUSPhoneFormats(String phoneNumber) {
assertTrue(US_PHONE_FULL.matcher(phoneNumber).matches(),
"Should match US phone format: " + phoneNumber);
}
@ParameterizedTest
@DisplayName("Test international phone number formats")
@ValueSource(strings = {
"+1 123 456 7890", // US with country code
"+44 20 7946 0958", // UK London
"+49 30 12345678", // Germany Berlin
"+33 1 42 86 83 26", // France Paris
"+81 3 1234 5678" // Japan Tokyo
})
void testInternationalPhoneFormats(String phoneNumber) {
assertTrue(INTERNATIONAL_PHONE.matcher(phoneNumber).matches(),
"Should match international phone format: " + phoneNumber);
}
@ParameterizedTest
@DisplayName("Test invalid phone number formats")
@ValueSource(strings = {
"123", // too short
"abc-def-ghij", // letters instead of numbers
"123-45-67890", // wrong grouping
"123 456 78901", // too many digits
"+", // just plus sign
"++1 123 456 7890" // double plus
})
void testInvalidPhoneFormats(String phoneNumber) {
assertFalse(US_PHONE_FULL.matcher(phoneNumber).matches(),
"Should not match invalid phone format: " + phoneNumber);
}
@Test
@DisplayName("Test phone number extraction from text")
void testPhoneNumberExtraction() {
var text = "Call me at (555) 123-4567 or reach John at +1-800-555-0199 for support.";
var matcher = US_PHONE_FULL.matcher(text);
assertTrue(matcher.find(), "Should find first phone number");
System.out.println("Found phone: " + matcher.group());
// Reset matcher to find all occurrences
matcher.reset();
int count = 0;
while (matcher.find()) {
count++;
System.out.printf("Phone %d: %s (positions %d-%d)%n",
count, matcher.group(), matcher.start(), matcher.end());
}
assertTrue(count > 0, "Should find at least one phone number");
}
}6.3. Check for a certain number range
The following example will check if a text contains a number with 3 digits.
Create the Java project
de.vogella.regex.numbermatch
and
the
following class.
package de.vogella.regex.numbermatch;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.junit.Test;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertTrue;
public class CheckNumber {
@Test
public void testSimpleTrue() {
String s= "1233";
assertTrue(test(s));
s= "0";
assertFalse(test(s));
s = "29 Kasdkf 2300 Kdsdf";
assertTrue(test(s));
s = "99900234";
assertTrue(test(s));
}
public static boolean test (String s){
Pattern pattern = Pattern.compile("\\d{3}");
Matcher matcher = pattern.matcher(s);
if (matcher.find()){
return true;
}
return false;
}
}6.4. Building a link checker
The following example allows you to extract all valid links from a webpage. It does not consider links which start with "javascript:" or "mailto:".
Create a Java project called de.vogella.regex.weblinks and the following class:
package de.vogella.regex.weblinks;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Pattern;
/**
* Modern link extractor using Java 11+ HttpClient and improved regex patterns.
* Extracts links from web pages while filtering out unwanted protocols.
*/
public class LinkGetter {
// More robust HTML link pattern
private static final Pattern LINK_PATTERN = Pattern.compile(
"<a\\s+(?:[^>]*?\\s+)?href=([\"'])(.*?)\\1[^>]*>",
Pattern.CASE_INSENSITIVE | Pattern.DOTALL
);
// Pattern to exclude unwanted link types
private static final Pattern EXCLUDED_PROTOCOLS = Pattern.compile(
"^(?:javascript:|mailto:|tel:|ftp:).*",
Pattern.CASE_INSENSITIVE
);
private final HttpClient httpClient;
public LinkGetter() {
this.httpClient = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.followRedirects(HttpClient.Redirect.NORMAL)
.build();
}
/**
* Extracts all valid HTTP/HTTPS links from the given URL
*/
public List<String> getLinks(String url) {
try {
var htmlContent = fetchWebPage(url);
return extractLinksFromHtml(htmlContent, url);
} catch (Exception e) {
System.err.println("Error fetching links from " + url + ": " + e.getMessage());
return new ArrayList<>();
}
}
/**
* Fetches web page content using modern HttpClient
*/
private String fetchWebPage(String url) throws IOException, InterruptedException {
try {
var request = HttpRequest.newBuilder()
.uri(URI.create(url))
.timeout(Duration.ofSeconds(30))
.header("User-Agent", "Java-LinkExtractor/1.0")
.GET()
.build();
var response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() == 200) {
return response.body();
} else {
throw new IOException("HTTP " + response.statusCode() + " for " + url);
}
} catch (URISyntaxException e) {
throw new IOException("Invalid URL: " + url, e);
}
}
/**
* Extracts links from HTML content using regex
*/
private List<String> extractLinksFromHtml(String html, String baseUrl) {
var links = new ArrayList<String>();
var matcher = LINK_PATTERN.matcher(html);
while (matcher.find()) {
var link = matcher.group(2); // The href value
if (isValidLink(link)) {
try {
var absoluteLink = makeAbsolute(baseUrl, link);
if (!links.contains(absoluteLink)) {
links.add(absoluteLink);
}
} catch (Exception e) {
// Skip invalid links
System.err.println("Skipping invalid link: " + link + " (" + e.getMessage() + ")");
}
}
}
return links;
}
/**
* Validates if a link should be included in results
*/
private boolean isValidLink(String link) {
if (link == null || link.trim().isEmpty()) {
return false;
}
var trimmedLink = link.trim();
// Exclude unwanted protocols
if (EXCLUDED_PROTOCOLS.matcher(trimmedLink).matches()) {
return false;
}
// Exclude anchors and empty hrefs
if (trimmedLink.equals("#") || trimmedLink.startsWith("#")) {
return false;
}
return true;
}
/**
* Converts relative URLs to absolute URLs using modern URI handling
*/
private String makeAbsolute(String baseUrl, String link) throws URISyntaxException {
var baseUri = new URI(baseUrl);
var linkUri = new URI(link);
// If link is already absolute, return as-is
if (linkUri.isAbsolute()) {
return linkUri.toString();
}
// Resolve relative URL against base URL
var resolvedUri = baseUri.resolve(linkUri);
return resolvedUri.toString();
}
/**
* Demonstration method showing usage
*/
public static void main(String[] args) {
var linkGetter = new LinkGetter();
// Example usage - replace with actual URL
var testUrl = "https://httpbin.org/links/10/0"; // Test URL with links
System.out.println("Extracting links from: " + testUrl);
var links = linkGetter.getLinks(testUrl);
System.out.println("Found " + links.size() + " links:");
links.forEach(link -> System.out.println(" " + link));
}
// Close resources
public void close() {
// HttpClient doesn't need explicit closing in Java 11+
// but included for completeness
}
}6.5. Finding duplicated words
The following regular expression matches duplicated words.
\b(\w+)\s+\1\b\b
is a word boundary and
\1
references to the captured match
of
the
first group, i.e., the first
word.
The
(?!-in)\b(\w+) \1\b
finds duplicate words if they do not start with "-in".
TIP:Add
(?s)
to search across multiple lines.
6.6. Finding elements which start in a new line
The following regular expression allows you to find the "title" word, in case it starts in a new line, potentially with leading spaces.
(\n\s*)title6.7. Finding (Non-Javadoc) statements
Sometimes (Non-Javadoc) are used in Java source code to indicate that
the method overrides a super method. As of Java 1.6 this can be done
via the
@Override
annotation and it is possible to remove these statements from your
code. The following regular expression can be used to identify these
statements.
(?s) /\* \(non-Javadoc\).*?\*/6.7.1. Replacing the DocBook table statement with Asciidoc
You can replace statements like the following:
<programlisting language="java">
<xi:include xmlns:xi="https://www.w3.org/2001/XInclude" parse="text" href="./examples/statements/MyClass.java" />
</programlisting>Corresponding regex:
`\s+<programlisting language="java">\R.\s+<xi:include xmlns:xi="https://www\.w3\.org/2001/XInclude" parse="text" href="\./examples/(.*).\s+/>\R.\s+</programlisting>`Target could be your example:
`\R[source,java]\R----\R include::res/$1[]\R----6.8. Modern regex patterns
The following examples demonstrate practical regex patterns commonly used in modern Java applications.
6.8.1. Email validation and data extraction
This comprehensive example shows email validation, URL validation, IPv4 address validation, and various data extraction patterns.
package de.vogella.regex.modern;
import java.util.regex.Pattern;
import java.util.List;
import java.util.ArrayList;
import java.util.regex.Matcher;
/**
* Demonstrates modern regex patterns for common validation scenarios.
* Includes email validation, URL validation, and data extraction patterns.
*/
public class ModernRegexExamples {
// Email validation pattern (basic but practical)
private static final Pattern EMAIL_PATTERN = Pattern.compile(
"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$"
);
// URL validation pattern
private static final Pattern URL_PATTERN = Pattern.compile(
"^https?://[a-zA-Z0-9.-]+(?:\\.[a-zA-Z]{2,})+(?:/[^\\s]*)?$"
);
// IPv4 address pattern
private static final Pattern IPV4_PATTERN = Pattern.compile(
"^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$"
);
// Credit card number pattern (digits with optional spaces/dashes)
private static final Pattern CREDIT_CARD_PATTERN = Pattern.compile(
"^\\d{4}[\\s-]?\\d{4}[\\s-]?\\d{4}[\\s-]?\\d{4}$"
);
// Log entry pattern for parsing
private static final Pattern LOG_PATTERN = Pattern.compile(
"^(\\d{4}-\\d{2}-\\d{2})\\s+(\\d{2}:\\d{2}:\\d{2})\\s+\\[(\\w+)\\]\\s+(.+)$"
);
public static boolean isValidEmail(String email) {
return email != null && EMAIL_PATTERN.matcher(email).matches();
}
public static boolean isValidUrl(String url) {
return url != null && URL_PATTERN.matcher(url).matches();
}
public static boolean isValidIPv4(String ip) {
return ip != null && IPV4_PATTERN.matcher(ip).matches();
}
public static boolean isValidCreditCard(String cardNumber) {
return cardNumber != null && CREDIT_CARD_PATTERN.matcher(cardNumber).matches();
}
/**
* Extracts structured data from log entries
*/
public static class LogEntry {
public final String date;
public final String time;
public final String level;
public final String message;
public LogEntry(String date, String time, String level, String message) {
this.date = date;
this.time = time;
this.level = level;
this.message = message;
}
@Override
public String toString() {
return String.format("LogEntry{date='%s', time='%s', level='%s', message='%s'}",
date, time, level, message);
}
}
public static LogEntry parseLogEntry(String logLine) {
var matcher = LOG_PATTERN.matcher(logLine);
if (matcher.matches()) {
return new LogEntry(
matcher.group(1), // date
matcher.group(2), // time
matcher.group(3), // level
matcher.group(4) // message
);
}
return null;
}
/**
* Extracts all email addresses from text
*/
public static List<String> extractEmails(String text) {
var emails = new ArrayList<String>();
var pattern = Pattern.compile("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}");
var matcher = pattern.matcher(text);
while (matcher.find()) {
emails.add(matcher.group());
}
return emails;
}
/**
* Masks sensitive data in text (like credit card numbers)
*/
public static String maskCreditCards(String text) {
var pattern = Pattern.compile("\\b\\d{4}[\\s-]?\\d{4}[\\s-]?\\d{4}[\\s-]?\\d{4}\\b");
return pattern.matcher(text).replaceAll("****-****-****-****");
}
public static void main(String[] args) {
System.out.println("=== Modern Regex Examples ===");
// Email validation
System.out.println("\n--- Email Validation ---");
var emails = List.of("user@example.com", "invalid.email", "test@domain.co.uk");
for (var email : emails) {
System.out.printf("%-20s -> %s%n", email, isValidEmail(email) ? "VALID" : "INVALID");
}
// URL validation
System.out.println("\n--- URL Validation ---");
var urls = List.of("https://www.example.com", "https://test.org/path", "ftp://invalid");
for (var url : urls) {
System.out.printf("%-30s -> %s%n", url, isValidUrl(url) ? "VALID" : "INVALID");
}
// Log parsing
System.out.println("\n--- Log Entry Parsing ---");
var logLines = List.of(
"2024-01-15 10:30:45 [INFO] Application started successfully",
"2024-01-15 10:30:50 [ERROR] Database connection failed",
"invalid log line"
);
for (var line : logLines) {
var entry = parseLogEntry(line);
if (entry != null) {
System.out.println("Parsed: " + entry);
} else {
System.out.println("Failed to parse: " + line);
}
}
// Email extraction
System.out.println("\n--- Email Extraction ---");
var text = "Contact us at support@company.com or sales@company.com for assistance.";
var foundEmails = extractEmails(text);
System.out.println("Found emails: " + foundEmails);
// Credit card masking
System.out.println("\n--- Credit Card Masking ---");
var sensitiveText = "My card number is 1234 5678 9012 3456 and expires soon.";
var maskedText = maskCreditCards(sensitiveText);
System.out.println("Original: " + sensitiveText);
System.out.println("Masked: " + maskedText);
}
}And the corresponding test class demonstrates how to properly test regex patterns:
package de.vogella.regex.modern;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
import static org.junit.jupiter.api.Assertions.*;
@DisplayName("Modern Regex Examples Tests")
public class ModernRegexExamplesTest {
@ParameterizedTest
@DisplayName("Should validate correct email addresses")
@ValueSource(strings = {
"user@example.com",
"test.email@domain.co.uk",
"name+tag@company.org",
"123@numbers.net"
})
void testValidEmails(String email) {
assertTrue(ModernRegexExamples.isValidEmail(email),
"Should validate email: " + email);
}
@ParameterizedTest
@DisplayName("Should reject invalid email addresses")
@ValueSource(strings = {
"invalid.email",
"@domain.com",
"user@",
"user@domain",
"user name@domain.com"
})
void testInvalidEmails(String email) {
assertFalse(ModernRegexExamples.isValidEmail(email),
"Should reject invalid email: " + email);
}
@ParameterizedTest
@DisplayName("Should validate correct URLs")
@ValueSource(strings = {
"https://www.example.com",
"https://test.org",
"https://subdomain.domain.co.uk/path/to/resource"
})
void testValidUrls(String url) {
assertTrue(ModernRegexExamples.isValidUrl(url),
"Should validate URL: " + url);
}
@ParameterizedTest
@DisplayName("Should reject invalid URLs")
@ValueSource(strings = {
"ftp://example.com",
"www.example.com",
"https://",
"not-a-url"
})
void testInvalidUrls(String url) {
assertFalse(ModernRegexExamples.isValidUrl(url),
"Should reject invalid URL: " + url);
}
@ParameterizedTest
@DisplayName("Should validate correct IPv4 addresses")
@ValueSource(strings = {
"192.168.1.1",
"10.0.0.1",
"255.255.255.255",
"0.0.0.0"
})
void testValidIPv4(String ip) {
assertTrue(ModernRegexExamples.isValidIPv4(ip),
"Should validate IPv4: " + ip);
}
@ParameterizedTest
@DisplayName("Should reject invalid IPv4 addresses")
@ValueSource(strings = {
"256.1.1.1",
"192.168.1",
"192.168.1.1.1",
"not.an.ip.address"
})
void testInvalidIPv4(String ip) {
assertFalse(ModernRegexExamples.isValidIPv4(ip),
"Should reject invalid IPv4: " + ip);
}
@Test
@DisplayName("Should parse valid log entries")
void testLogEntryParsing() {
var logLine = "2024-01-15 10:30:45 [INFO] Application started successfully";
var entry = ModernRegexExamples.parseLogEntry(logLine);
assertNotNull(entry, "Should parse valid log entry");
assertEquals("2024-01-15", entry.date);
assertEquals("10:30:45", entry.time);
assertEquals("INFO", entry.level);
assertEquals("Application started successfully", entry.message);
}
@Test
@DisplayName("Should return null for invalid log entries")
void testInvalidLogEntry() {
var invalidLog = "This is not a valid log entry";
var entry = ModernRegexExamples.parseLogEntry(invalidLog);
assertNull(entry, "Should return null for invalid log entry");
}
@Test
@DisplayName("Should extract all email addresses from text")
void testEmailExtraction() {
var text = "Contact support@company.com or sales@company.com for help. Also try info@help.org.";
var emails = ModernRegexExamples.extractEmails(text);
assertEquals(3, emails.size(), "Should find 3 email addresses");
assertTrue(emails.contains("support@company.com"));
assertTrue(emails.contains("sales@company.com"));
assertTrue(emails.contains("info@help.org"));
}
@Test
@DisplayName("Should mask credit card numbers in text")
void testCreditCardMasking() {
var text = "My card is 1234 5678 9012 3456 and backup is 9876-5432-1098-7654.";
var masked = ModernRegexExamples.maskCreditCards(text);
assertFalse(masked.contains("1234 5678 9012 3456"),
"Should mask first credit card number");
assertFalse(masked.contains("9876-5432-1098-7654"),
"Should mask second credit card number");
assertTrue(masked.contains("****-****-****-****"),
"Should contain masked placeholders");
}
}6.8.2. Key takeaways from modern regex usage
-
Pre-compile patterns: Use
Pattern.compile()for patterns used multiple times -
Use descriptive names: Give meaningful names to your regex patterns
-
Test thoroughly: Include comprehensive test cases covering edge cases
-
Document complex patterns: Comment complex regex patterns to explain their purpose
-
Consider security: Be aware of ReDoS (Regular Expression Denial of Service) attacks
-
Performance matters: Profile regex usage in performance-critical code paths
6.8.3. Stream integration with regex
Java Streams work well with regex patterns for processing collections of text:
// Example: Filter and extract emails from a list of strings
List<String> texts = Arrays.asList(
"Contact us at support@company.com",
"Invalid email: not-an-email",
"Sales: sales@company.com"
);
Pattern emailPattern = Pattern.compile("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}");
List<String> emails = texts.stream()
.map(emailPattern::matcher)
.filter(Matcher::find)
.map(matcher -> matcher.group())
.collect(Collectors.toList());7. Best Practices and Common Pitfalls
7.1. Security considerations
7.1.1. ReDoS (Regular Expression Denial of Service)
Poorly written regex patterns can cause exponential time complexity, leading to DoS attacks. Patterns with nested quantifiers are particularly vulnerable.
// DANGEROUS: Can cause catastrophic backtracking
Pattern dangerous = Pattern.compile("(a+)+");
// SAFER: Use possessive quantifiers or atomic groups
Pattern safer = Pattern.compile("(a++)");
Pattern atomic = Pattern.compile("(?>a+)");7.1.2. Input validation best practices
-
Validate input length: Set maximum input size before applying regex
-
Use timeouts: Set timeouts for regex operations on untrusted input
-
Sanitize patterns: If allowing user-defined patterns, validate them first
-
Test with edge cases: Test patterns with malicious inputs
// Example with timeout and length validation
public boolean validateWithTimeout(String input, Pattern pattern) {
if (input.length() > 10000) {
throw new IllegalArgumentException("Input too long");
}
// In practice, you'd use a separate thread or async execution
// This is a simplified example
long start = System.currentTimeMillis();
boolean matches = pattern.matcher(input).matches();
long duration = System.currentTimeMillis() - start;
if (duration > 1000) { // 1 second timeout
throw new RuntimeException("Regex timeout");
}
return matches;
}7.2. Performance optimization
7.2.1. Pattern compilation
// BAD: Compiling pattern repeatedly
public boolean validateEmails(List<String> emails) {
for (String email : emails) {
if (email.matches("^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$")) {
return true;
}
}
return false;
}
// GOOD: Compile once, reuse many times
private static final Pattern EMAIL_PATTERN = Pattern.compile(
"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$"
);
public boolean validateEmails(List<String> emails) {
Matcher matcher = EMAIL_PATTERN.matcher("");
for (String email : emails) {
if (matcher.reset(email).matches()) {
return true;
}
}
return false;
}7.2.2. Efficient quantifiers
// Less efficient: Backtracking possible
Pattern.compile(".*abc.*");
// More efficient: Possessive quantifier
Pattern.compile(".*+abc.*");
// Alternative: Non-capturing group with specific bounds
Pattern.compile("[\\s\\S]{0,1000}abc[\\s\\S]*");7.3. Common mistakes and solutions
7.3.1. Escaping issues
// WRONG: Single backslash in Java string
String regex = "\d+"; // This won't compile!
// CORRECT: Double backslash for regex meta-characters
String regex = "\\d+";
// ALTERNATIVE: Use Pattern.quote() for literal strings
String literal = "file.txt";
String regex = Pattern.quote(literal); // Escapes all meta-characters7.3.2. Greedy vs. reluctant quantifiers
String html = "<div>content</div><span>more</span>";
// Greedy: Matches from first < to last >
Pattern greedy = Pattern.compile("<.*>");
// Result: "<div>content</div><span>more</span>"
// Reluctant: Matches shortest possible
Pattern reluctant = Pattern.compile("<.*?>");
// Results: "<div>", "</div>", "<span>", "</span>"
// Most specific: Use character classes
Pattern specific = Pattern.compile("<[^>]*>");
// More efficient and precise7.3.3. Anchor confusion
// matches() checks entire string (implicit anchors)
"hello world".matches("hello"); // false - doesn't match entire string
"hello".matches("hello"); // true
// find() searches within string
Pattern.compile("hello").matcher("hello world").find(); // true
// Explicit anchors for clarity
Pattern.compile("^hello$").matcher("hello").matches(); // true7.4. Testing regex patterns
7.4.1. Comprehensive test coverage
@ParameterizedTest
@DisplayName("Email validation edge cases")
@ValueSource(strings = {
"simple@example.com", // Basic valid email
"user.name@domain.co.uk", // With dots and multiple TLD
"user+tag@domain.org", // With plus sign
"user@domain-name.com", // Domain with hyphen
"", // Empty string
"@domain.com", // Missing local part
"user@", // Missing domain
"user@domain", // Missing TLD
"user name@domain.com", // Space in local part
"user@domain..com" // Double dot in domain
})
void testEmailValidation(String email) {
// Test with expected results
}7.4.2. Pattern debugging tools
// Enable pattern debugging
System.setProperty("java.util.regex.Pattern.debug", "true");
// Use named groups for clarity (Java 7+)
Pattern namedPattern = Pattern.compile(
"(?<year>\\d{4})-(?<month>\\d{2})-(?<day>\\d{2})"
);
Matcher matcher = namedPattern.matcher("2024-01-15");
if (matcher.matches()) {
String year = matcher.group("year");
String month = matcher.group("month");
String day = matcher.group("day");
}7.5. Alternatives to regex
Sometimes regex isn’t the best solution:
-
Simple string operations: Use
String.contains(),String.startsWith(), etc. -
JSON/XML parsing: Use dedicated parsers like Jackson or JAXB
-
CSV parsing: Use libraries like OpenCSV
-
Complex parsing: Consider parser generators like ANTLR
// Instead of regex for simple checks:
if (text.matches(".*error.*")) { /* ... */ }
// Use simpler string method:
if (text.contains("error")) { /* ... */ }
// For complex structured data, use proper parsers:
// Instead of regex for JSON: "\\{.*\"name\"\\s*:\\s*\"([^\"]+)\".*\\}"
// Use: ObjectMapper mapper = new ObjectMapper(); JsonNode node = mapper.readTree(json);8. Processing regular expressions in Eclipse
The Eclipse IDE allows to perform search and replace across a set of files using regular expressions. In Eclipse use the Ctrl+H shortcut to open the Search dialog.
Select the File Search tab and check the Regular expression flag before entering your regular expression. You can also specify the file type and the scope for the search and replace operation.
The following screenshots demonstrate how to search for the <![CDATA[]]]> XML tag with leading whitespace and how to remove the whitespace.
image::regularexpressioneclipse10.png[Search and replace in Eclipse part 1,pdfwidth=40%}
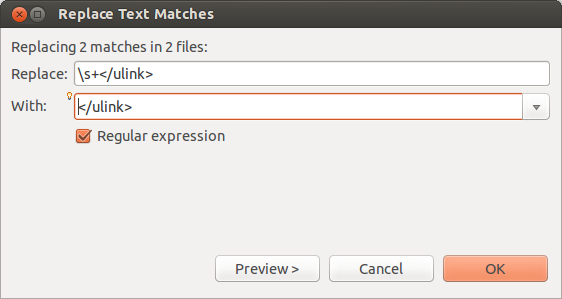
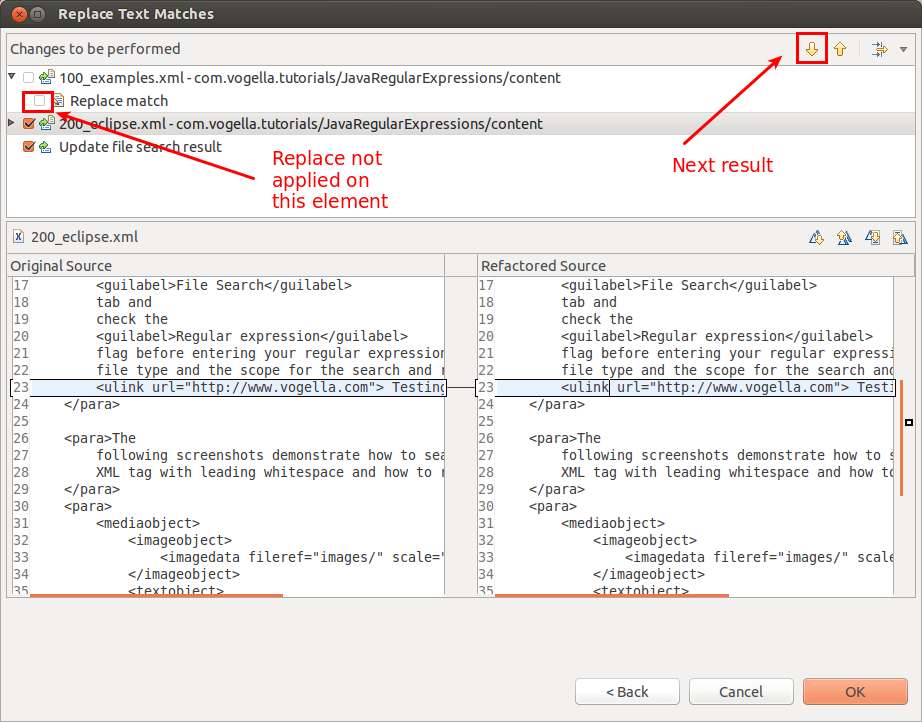
The resulting dialog allows you to review the changes and remove elements which should not be replaced.
If you press the OK button, the changes are applied.
9. Links and Literature
9.1. vogella Java example code
If you need more assistance we offer Online Training and Onsite training as well as consulting